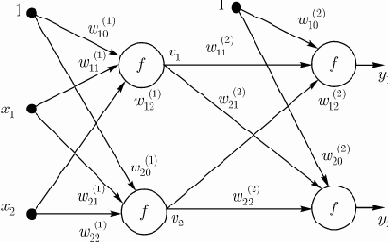
Возьмем двухслойную сеть (рис. 1) (входной слой не рассматривается). Веса нейронов первого (скрытого) слоя пометим верхним индексом (1), а выходного слоя - верхним индексом (2). Выходные сигналы скрытого слоя обозначим
, а выходного слоя -
. Будем считать, что функция активации нейронов задана в сигмоидальной униполярной или биполярной форме. Для упрощения описания будем использовать расширенное обозначение входного вектора сети в виде
, где
соответствует порогу. С вектором
связаны два выходных вектора сети: вектор фактических выходных сигналов
и вектор ожидаемых выходных сигналов
.
Цель обучения состоит в подборе таких значений весов
и
для всех слоев сети, чтобы при заданном входном векторе
получить на выходе значения сигналов
, которые с требуемой точностью будут совпадать с ожидаемыми значениями
для
. Выходной сигнал
-го нейрона скрытого слоя описывается функцией
Рис. 1. Пример двухслойной нейронной сети
В выходном слое
-й нейрон вырабатывает выходной сигнал
Из формулы следует, что на значение выходного сигнала влияют веса обоих слоев, тогда как сигналы, вырабатываемые в скрытом слое, не зависят от весов выходного слоя.
Основу алгоритма обратного распространения ошибки составляет целевая функция, формулируемая, как правило, в виде квадратичной суммы разностей между фактическими и ожидаемыми значениями выходных сигналов. Для обучающей выборки, состоящей из
примеров, целевая функция имеет вид
Минимизация целевой функции достигается уточнением вектора весов (обучением) по формуле
где
(1)
- коэффициент обучения, а
- направление в пространстве весов
. Выбор этого направления обычно основан на определении градиента целевой функции относительно весов всех слоев сети. Для весов выходного слоя задача имеет очевидное решение. Для других слоев используется алгоритм обратного распространения ошибки. Рассмотрим его на примере двухслойной сети. В этом случае при
целевая функция определяется выражением
(2)
4. Описанный процесс следует повторить для всех обучающих примеров задачника, продолжая его вплоть до выполнения условия остановки алгоритма. Действие алгоритма завершается в момент, когда норма градиента упадет ниже априори заданного значения, характеризующего точность процесса обучения.
Руководствуясь рис. 2, можно легко определить все компоненты градиента целевой функции, т.е. все частные производные функции
по весам сети. Для этого, двигаясь от входов сети (бывших выходов), нужно перемножить все встречающиеся на пути величины (кроме весов
, для которых рассчитывается частная производная
). Кроме того, там, где дуги сходятся к одной вершине, нужно выполнить сложение произведений, полученных на этих дугах.
Так, например, чтобы посчитать производную
, нужно перемножить величины
, а для вычисления производной
нужно посчитать произведения
и
и затем сложить эти произведения и результат умножить на